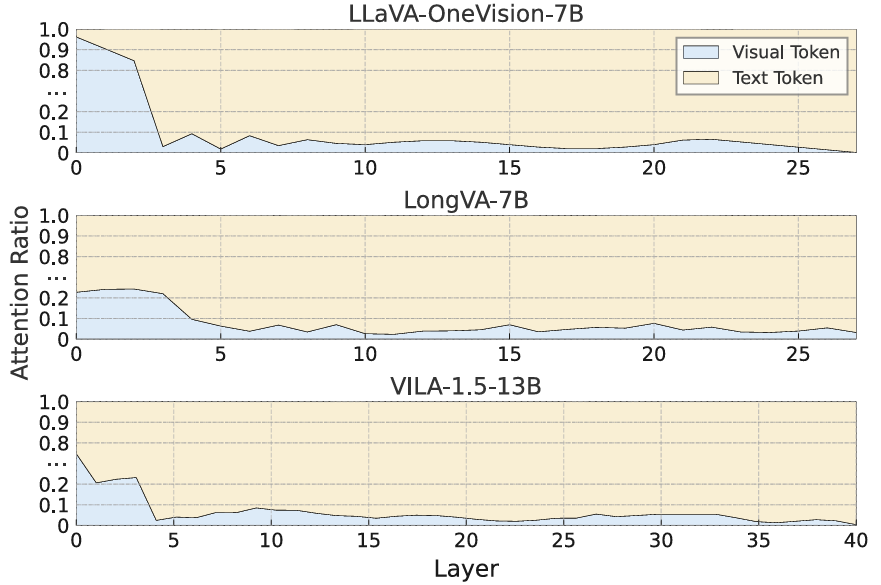
@misc{wang2025metokmultistageeventbasedtoken,title={METok: Multi-Stage Event-based Token Compression for Efficient Long Video Understanding},author={Wang, Mengyue and Chen, Shuo and Kersting, Kristian and Tresp, Volker and Ma, Yunpu},year={2025},eprint={2506.02850},archiveprefix={arXiv},primaryclass={cs.CV},url={https://arxiv.org/abs/2506.02850},}
Language Mixing in Reasoning Language Models: Patterns, Impact, and Internal Causes
@misc{wang2025languagemixingreasoninglanguage,title={Language Mixing in Reasoning Language Models: Patterns, Impact, and Internal Causes},author={Wang, Mingyang and Lange, Lukas and Adel, Heike and Ma, Yunpu and Strötgen, Jannik and Schütze, Hinrich},year={2025},eprint={2505.14815},archiveprefix={arXiv},primaryclass={cs.CL},url={https://arxiv.org/abs/2505.14815},}
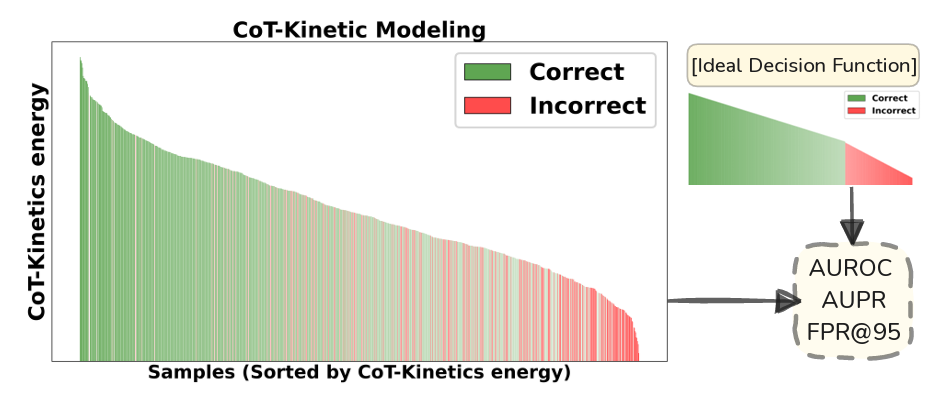
CoT-Kinetics: A Theoretical Modeling Assessing LRM Reasoning Process
@misc{bi2025cotkineticstheoreticalmodelingassessing,title={CoT-Kinetics: A Theoretical Modeling Assessing LRM Reasoning Process},author={Bi, Jinhe and Yan, Danqi and Wang, Yifan and Huang, Wenke and Chen, Haokun and Wan, Guancheng and Ye, Mang and Xiao, Xun and Schuetze, Hinrich and Tresp, Volker and Ma, Yunpu},year={2025},eprint={2505.13408},archiveprefix={arXiv},primaryclass={cs.AI},url={https://arxiv.org/abs/2505.13408},}
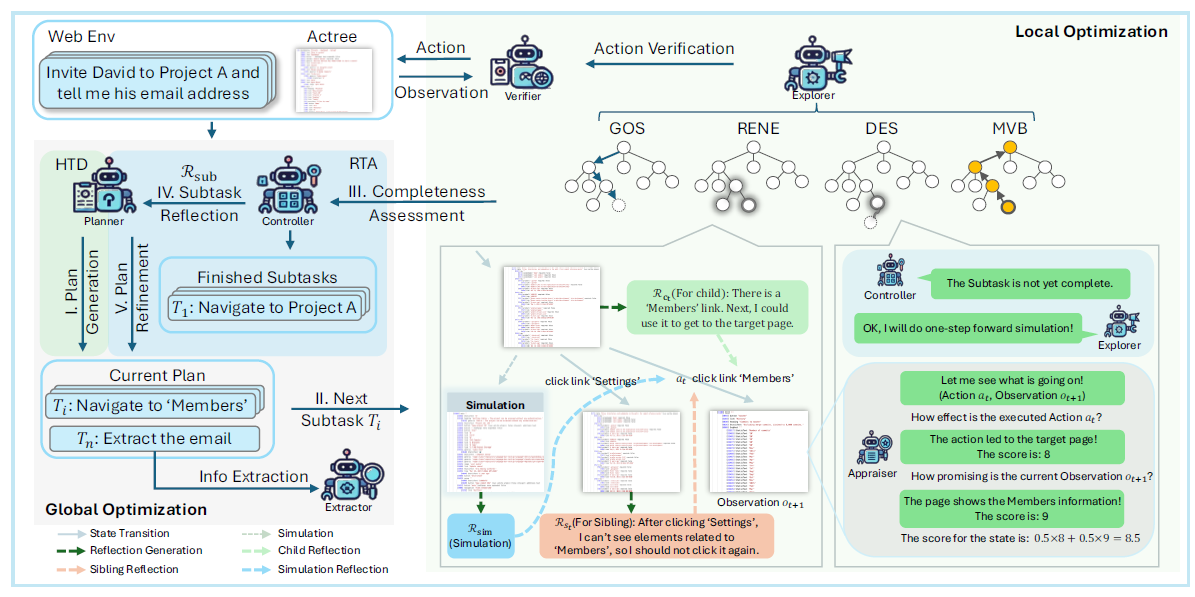
Webpilot: A versatile and autonomous multi-agent system for web task execution with strategic exploration
Yao Zhang, Zijian Ma, Yunpu Ma†, Zhen Han, Yu Wu, and Volker Tresp
In Proceedings of the AAAI Conference on Artificial Intelligence, 2025
@inproceedings{zhang2025webpilot,title={Webpilot: A versatile and autonomous multi-agent system for web task execution with strategic exploration},author={Zhang, Yao and Ma, Zijian and Ma, Yunpu and Han, Zhen and Wu, Yu and Tresp, Volker},booktitle={Proceedings of the AAAI Conference on Artificial Intelligence},volume={39},number={22},pages={23378--23386},year={2025},}
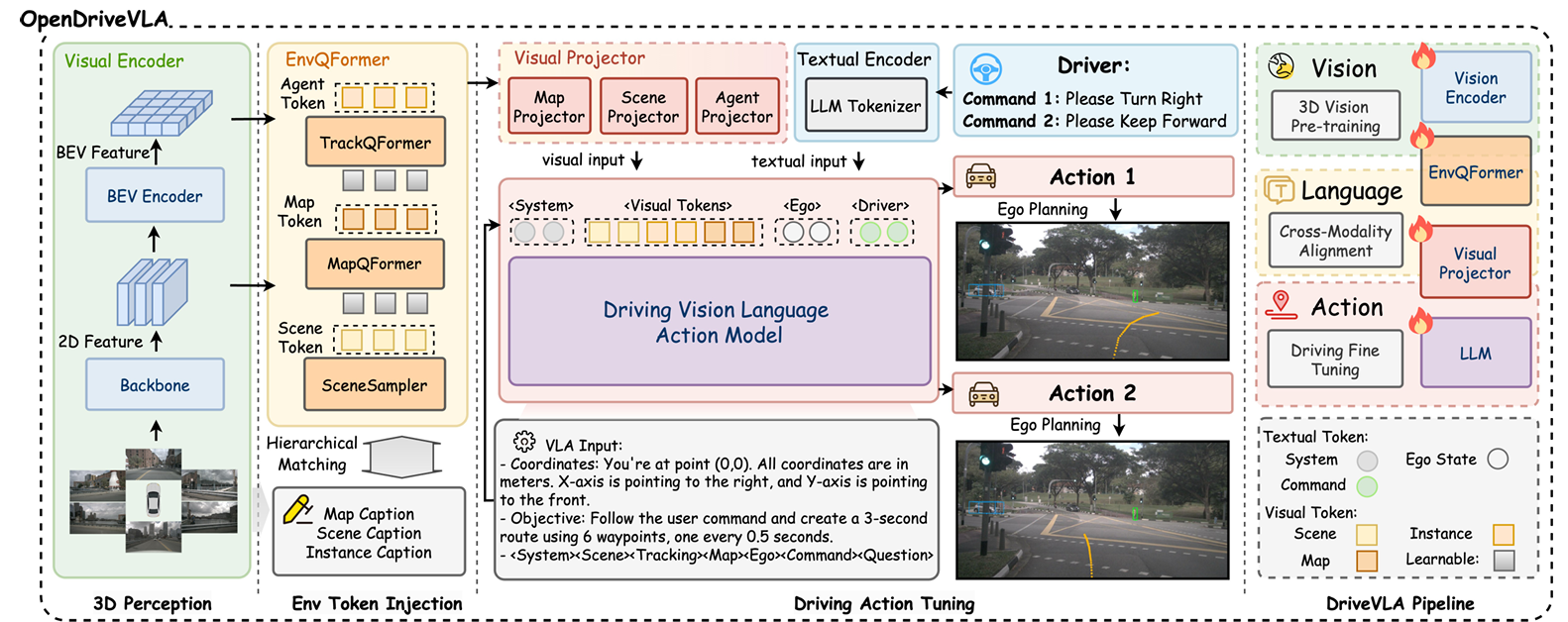
OpenDriveVLA: Towards End-to-end Autonomous Driving with Large Vision Language Action Model
Xingcheng Zhou, Xuyuan Han, Feng Yang, Yunpu Ma, and Alois C. Knoll
@misc{zhou2025opendrivevlaendtoendautonomousdriving,title={OpenDriveVLA: Towards End-to-end Autonomous Driving with Large Vision Language Action Model},author={Zhou, Xingcheng and Han, Xuyuan and Yang, Feng and Ma, Yunpu and Knoll, Alois C.},year={2025},eprint={2503.23463},archiveprefix={arXiv},primaryclass={cs.CV},url={https://arxiv.org/abs/2503.23463},}
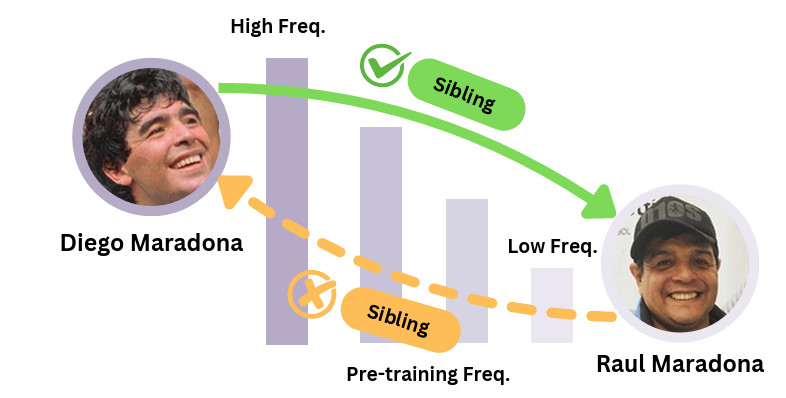
Supposedly Equivalent Facts That Aren’t? Entity Frequency in Pre-training Induces Asymmetry in LLMs
@misc{he2025supposedlyequivalentfactsarent,title={Supposedly Equivalent Facts That Aren't? Entity Frequency in Pre-training Induces Asymmetry in LLMs},author={He, Yuan and He, Bailan and Ding, Zifeng and Lupidi, Alisia and Zhu, Yuqicheng and Chen, Shuo and Zhang, Caiqi and Chen, Jiaoyan and Ma, Yunpu and Tresp, Volker and Horrocks, Ian},year={2025},eprint={2503.22362},archiveprefix={arXiv},primaryclass={cs.CL},url={https://arxiv.org/abs/2503.22362},}
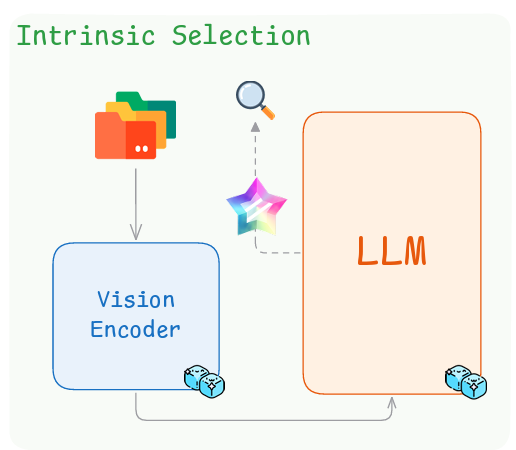
PRISM: Self-Pruning Intrinsic Selection Method for Training-Free Multimodal Data Selection
Jinhe Bi, Yifan Wang, Danqi Yan, Xun Xiao, Artur Hecker, Volker Tresp, and Yunpu Ma†
@misc{bi2025prismselfpruningintrinsicselection,title={PRISM: Self-Pruning Intrinsic Selection Method for Training-Free Multimodal Data Selection},author={Bi, Jinhe and Wang, Yifan and Yan, Danqi and Xiao, Xun and Hecker, Artur and Tresp, Volker and Ma, Yunpu},year={2025},eprint={2502.12119},archiveprefix={arXiv},primaryclass={cs.CV},url={https://arxiv.org/abs/2502.12119},}
LLaVA Steering: Visual Instruction Tuning with 500x Fewer Parameters through Modality Linear Representation-Steering
Jinhe Bi, Yujun Wang, Haokun Chen, Xun Xiao, Artur Hecker, Volker Tresp, and Yunpu Ma†
@misc{bi2025llavasteeringvisualinstruction,title={LLaVA Steering: Visual Instruction Tuning with 500x Fewer Parameters through Modality Linear Representation-Steering},author={Bi, Jinhe and Wang, Yujun and Chen, Haokun and Xiao, Xun and Hecker, Artur and Tresp, Volker and Ma, Yunpu},year={2025},booktitle={Annual Meeting of the Association for Computational Linguistics},primaryclass={cs.CV},url={https://arxiv.org/abs/2412.12359},}
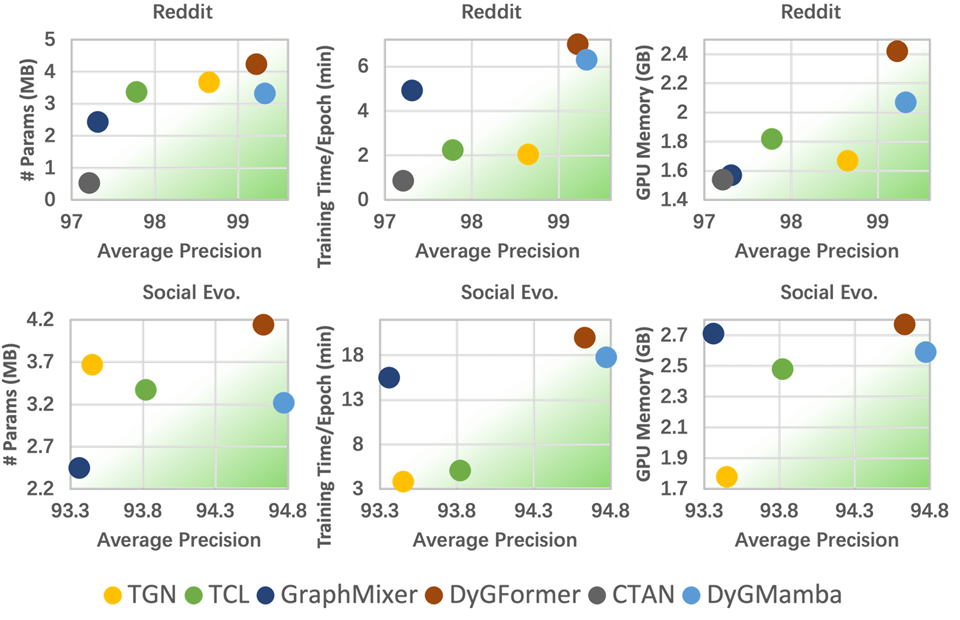
DyGMamba: Efficiently Modeling Long-Term Temporal Dependency on Continuous-Time Dynamic Graphs with State Space Models
Zifeng Ding, Yifeng Li, Yuan He, Antonio Norelli, Jingcheng Wu, Volker Tresp, Michael Bronstein, and Yunpu Ma†
@misc{ding2025dygmambaefficientlymodelinglongterm,title={DyGMamba: Efficiently Modeling Long-Term Temporal Dependency on Continuous-Time Dynamic Graphs with State Space Models},author={Ding, Zifeng and Li, Yifeng and He, Yuan and Norelli, Antonio and Wu, Jingcheng and Tresp, Volker and Bronstein, Michael and Ma, Yunpu},booktitle={Transactions on Machine Learning Research},year={2025},primaryclass={cs.LG},url={https://arxiv.org/abs/2408.04713},}
2024
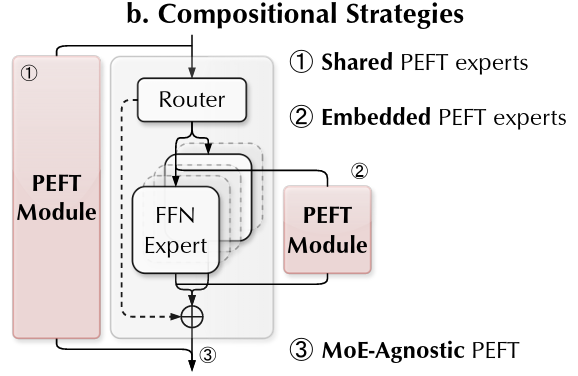
PERFT: Parameter-Efficient Routed Fine-Tuning for Mixture-of-Expert Model
@misc{liu2024perftparameterefficientroutedfinetuning,title={PERFT: Parameter-Efficient Routed Fine-Tuning for Mixture-of-Expert Model},author={Liu, Yilun and Ma, Yunpu and Chen, Shuo and Ding, Zifeng and He, Bailan and Han, Zhen and Tresp, Volker},year={2024},eprint={2411.08212},archiveprefix={arXiv},primaryclass={cs.LG},url={https://arxiv.org/abs/2411.08212},}
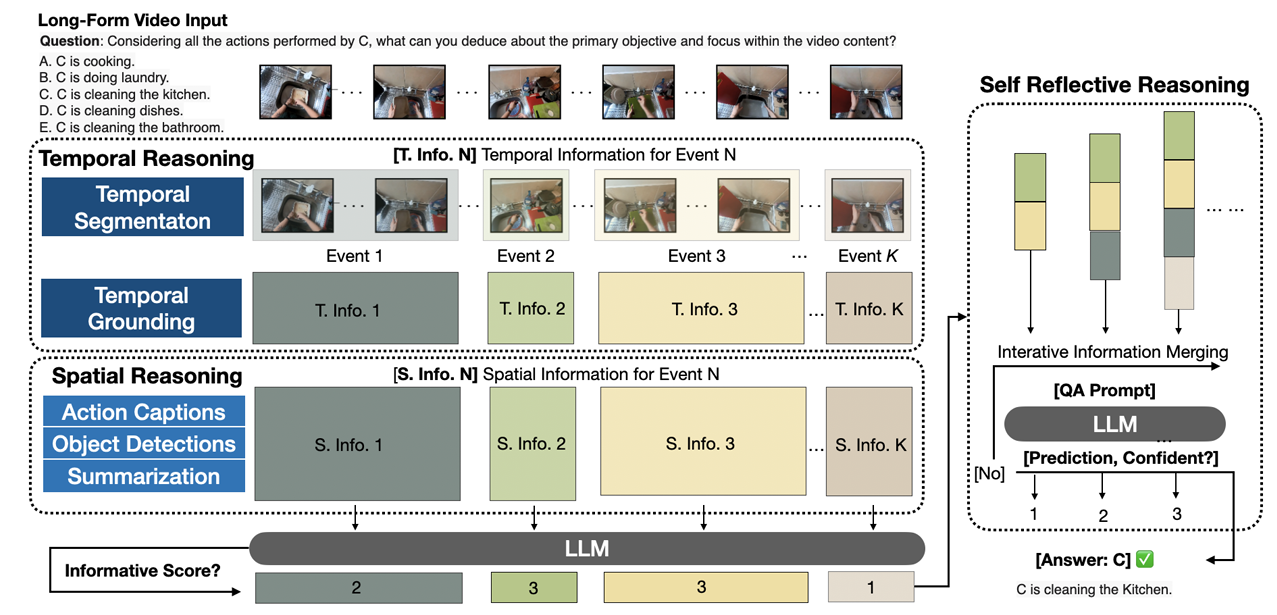
VideoINSTA: Zero-shot Long Video Understanding via Informative Spatial-Temporal Reasoning with LLMs
Ruotong Liao, Max Erler, Huiyu Wang, Guangyao Zhai, Gengyuan Zhang, Yunpu Ma†, and Volker Tresp
In Findings of the Association for Computational Linguistics: EMNLP 2024, Nov 2024
In the video-language domain, recent works in leveraging zero-shot Large Language Model-based reasoning for video understanding have become competitive challengers to previous end-to-end models. However, long video understanding presents unique challenges due to the complexity of reasoning over extended timespans, even for zero-shot LLM-based approaches. The challenge of information redundancy in long videos prompts the question of what specific information is essential for large language models (LLMs) and how to leverage them for complex spatial-temporal reasoning in long-form video analysis. We propose a framework VideoINSTA , i.e. INformative Spatial-TemporAl Reasoning for zero-shot long-form video understanding.VideoINSTA contributes (1) a zero-shot framework for long video understanding using LLMs; (2) an event-based temporalreasoning and content-based spatial reasoning approach for LLMs to reason over spatial-temporal information in videos; (3) a self-reflective information reasoning scheme based on information sufficiency and prediction confidence while balancing temporal factors.Our model significantly improves the state-of-the-art on three long video question-answering benchmarks: EgoSchema, NextQA, and IntentQA, and the open question answering dataset ActivityNetQA. Code is released: https://github.com/mayhugotong/VideoINSTA.
@inproceedings{liao-etal-2024-videoinsta,title={{V}ideo{INSTA}: Zero-shot Long Video Understanding via Informative Spatial-Temporal Reasoning with {LLM}s},author={Liao, Ruotong and Erler, Max and Wang, Huiyu and Zhai, Guangyao and Zhang, Gengyuan and Ma, Yunpu and Tresp, Volker},editor={Al-Onaizan, Yaser and Bansal, Mohit and Chen, Yun-Nung},booktitle={Findings of the Association for Computational Linguistics: EMNLP 2024},month=nov,year={2024},address={Miami, Florida, USA},publisher={Association for Computational Linguistics},url={https://aclanthology.org/2024.findings-emnlp.384/},doi={10.18653/v1/2024.findings-emnlp.384},pages={6577--6602},}